Function for prediction at new locations for univariate Gaussian spatially-varying coefficient models
predict.svcAbund.RdThe function predict collects posterior predictive samples for a set of new locations given an object of class `svcAbund`.
Usage
# S3 method for svcAbund
predict(object, X.0, coords.0, n.omp.threads = 1,
verbose = TRUE, n.report = 100, ignore.RE = FALSE,
z.0.samples, include.sp = TRUE, ...)Arguments
- object
an object of class svcAbund
- X.0
the design matrix of covariates at the prediction locations. This should include a column of 1s for the intercept if an intercept is included in the model. If random effects are included in the model, the levels of the random effects at the new locations should be included as a column in the design matrix. The ordering of the levels should match the ordering used to fit the data in
svcAbund. Columns should correspond to the order of how covariates were specified in the corresponding formula argument ofsvcAbund. Column names of all variables must match the names of variables used when fitting the model (for the intercept, use'(Intercept)').- coords.0
the spatial coordinates corresponding to
X.0. Note thatspAbundanceassumes coordinates are specified in a projected coordinate system.- n.omp.threads
a positive integer indicating the number of threads to use for SMP parallel processing. The package must be compiled for OpenMP support. For most Intel-based machines, we recommend setting
n.omp.threadsup to the number of hyperthreaded cores. Note,n.omp.threads> 1 might not work on some systems.- verbose
if
TRUE, model specification and progress of the sampler is printed to the screen. Otherwise, nothing is printed to the screen.- n.report
the interval to report sampling progress.
- ignore.RE
logical value that specifies whether or not to remove unstructured random effects from the subsequent predictions. If
TRUE, random effects will be included. IfFALSE, random effects will be set to 0 and predictions will only be generated from the fixed effects.- z.0.samples
a matrix with rows corresponding to MCMC samples and columns corresponding to prediction locations containing the full posterior samples of the predicted binary portion of a zero-inflated Gaussian model. In the context of abundance models, this typically corresponds to estimates of the presence or absence of the species at the location. When using
spOccupancyto generate the first stage samples of the zero-inflated Gaussian model, this is the object contained in thez.0.samplesobject of the predition function for th spOccupancy object. Ignored for all model types other than zero-inflated Gaussian.- include.sp
a logical value used to indicate whether spatial random effects should be included in the predictions. By default, this is set to
TRUE. If set toFALSE, predictions are given using the covariates and any unstructured random effects in the model. IfFALSE, thecoords.0argument is not required.- ...
currently no additional arguments
Note
When ignore.RE = FALSE, both sampled levels and non-sampled levels of random effects are supported for prediction. For sampled levels, the posterior distribution for the random intercept corresponding to that level of the random effect will be used in the prediction. For non-sampled levels, random values are drawn from a normal distribution using the posterior samples of the random effect variance, which results in fully propagated uncertainty in predictions with models that incorporate random effects.
Author
Jeffrey W. Doser doserjef@msu.edu,
Andrew O. Finley finleya@msu.edu,
Value
A list object of class predict.svcAbund. When type = 'abundance', the list consists of:
- mu.0.samples
a
codaobject of posterior predictive samples for the expected abundance values.- y.0.samples
a
codaobject of posterior predictive samples for the abundance values.- w.0.samples
a three-dimensional array of posterior predictive samples for the spatially-varying coefficients, with dimensions corresponding to MCMC iteration, coefficient, and site.
The return object will include additional objects used for standard extractor functions.
Examples
set.seed(1000)
# Sites
J.x <- 10
J.y <- 10
J <- J.x * J.y
# Occurrence --------------------------
beta <- c(10, 0.5, -0.2, 0.75)
p <- length(beta)
mu.RE <- list()
# Spatial parameters ------------------
sp <- TRUE
svc.cols <- c(1, 2)
p.svc <- length(svc.cols)
cov.model <- "exponential"
sigma.sq <- runif(p.svc, 0.4, 4)
phi <- runif(p.svc, 3/1, 3/0.7)
tau.sq <- 2
# Get all the data
dat <- simAbund(J.x = J.x, J.y = J.y, beta = beta, tau.sq = tau.sq,
mu.RE = mu.RE, sp = sp, svc.cols = svc.cols, family = 'Gaussian',
cov.model = cov.model, sigma.sq = sigma.sq, phi = phi)
# Prep the data for spAbundance -------------------------------------------
y <- dat$y
X <- dat$X
coords <- dat$coords
# Subset data for prediction if desired
pred.indx <- sample(1:J, round(J * .25), replace = FALSE)
y.0 <- y[pred.indx, drop = FALSE]
X.0 <- X[pred.indx, , drop = FALSE]
coords.0 <- coords[pred.indx, ]
y <- y[-pred.indx, drop = FALSE]
X <- X[-pred.indx, , drop = FALSE]
coords <- coords[-pred.indx, ]
# Package all data into a list
covs <- cbind(X)
colnames(covs) <- c('int', 'cov.1', 'cov.2', 'cov.3')
# Data list bundle
data.list <- list(y = y, covs = covs, coords = coords)
# Priors
prior.list <- list(beta.normal = list(mean = 0, var = 1000),
sigma.sq.ig = list(a = 2, b = 1), tau.sq = c(2, 1),
sigma.sq.mu.ig = list(a = 2, b = 1),
phi.unif = list(a = 3 / 1, b = 3 / 0.1))
# Starting values
inits.list <- list(beta = 0, alpha = 0,
sigma.sq = 1, phi = phi, tau.sq = 2, sigma.sq.mu = 0.5)
# Tuning
tuning.list <- list(phi = 1)
n.batch <- 10
batch.length <- 25
n.burn <- 100
n.thin <- 1
n.chains <- 3
out <- svcAbund(formula = ~ cov.1 + cov.2 + cov.3,
svc.cols = svc.cols,
data = data.list,
n.batch = n.batch,
batch.length = batch.length,
inits = inits.list,
priors = prior.list,
accept.rate = 0.43,
family = 'Gaussian',
cov.model = "exponential",
tuning = tuning.list,
n.omp.threads = 1,
verbose = TRUE,
NNGP = TRUE,
n.neighbors = 5,
n.report = 25,
n.burn = n.burn,
n.thin = n.thin,
n.chains = n.chains)
#> ----------------------------------------
#> Preparing to run the model
#> ----------------------------------------
#> No prior specified for tau.sq.
#> Using an inverse-Gamma prior with the shape parameter set to 2 and scale parameter to 0.5.
#> w is not specified in initial values.
#> Setting initial value to 0
#> ----------------------------------------
#> Building the neighbor list
#> ----------------------------------------
#> ----------------------------------------
#> Building the neighbors of neighbors list
#> ----------------------------------------
#> ----------------------------------------
#> Model description
#> ----------------------------------------
#> Spatial NNGP model with 75 sites.
#>
#> Samples per chain: 250 (10 batches of length 25)
#> Burn-in: 100
#> Thinning Rate: 1
#> Number of Chains: 3
#> Total Posterior Samples: 450
#>
#> Number of spatially-varying coefficients: 2
#> Using the exponential spatial correlation model.
#>
#> Using 5 nearest neighbors.
#>
#> Source compiled with OpenMP support and model fit using 1 thread(s).
#>
#> Adaptive Metropolis with target acceptance rate: 43.0
#> ----------------------------------------
#> Chain 1
#> ----------------------------------------
#> Sampling ...
#> Batch: 10 of 10, 100.00%
#> ----------------------------------------
#> Chain 2
#> ----------------------------------------
#> Sampling ...
#> Batch: 10 of 10, 100.00%
#> ----------------------------------------
#> Chain 3
#> ----------------------------------------
#> Sampling ...
#> Batch: 10 of 10, 100.00%
# Predict at new values ---------------------------------------------------
out.pred <- predict(out, X.0, coords.0)
#> ----------------------------------------
#> Prediction description
#> ----------------------------------------
#> NNGP Model fit with 75 observations.
#>
#> Number of covariates: 4 (including intercept if specified).
#>
#> Number of spatially-varying coefficients: 2 (including intercept if specified).
#>
#> Using the exponential spatial correlation model.
#>
#> Using 5 nearest neighbors.
#>
#> Number of MCMC samples: 450.
#>
#> Predicting at 25 locations.
#>
#>
#> Source compiled with OpenMP support and model fit using 1 threads.
#> -------------------------------------------------
#> Predicting
#> -------------------------------------------------
#> Location: 25 of 25, 100.00%
#> Generating abundance estimates
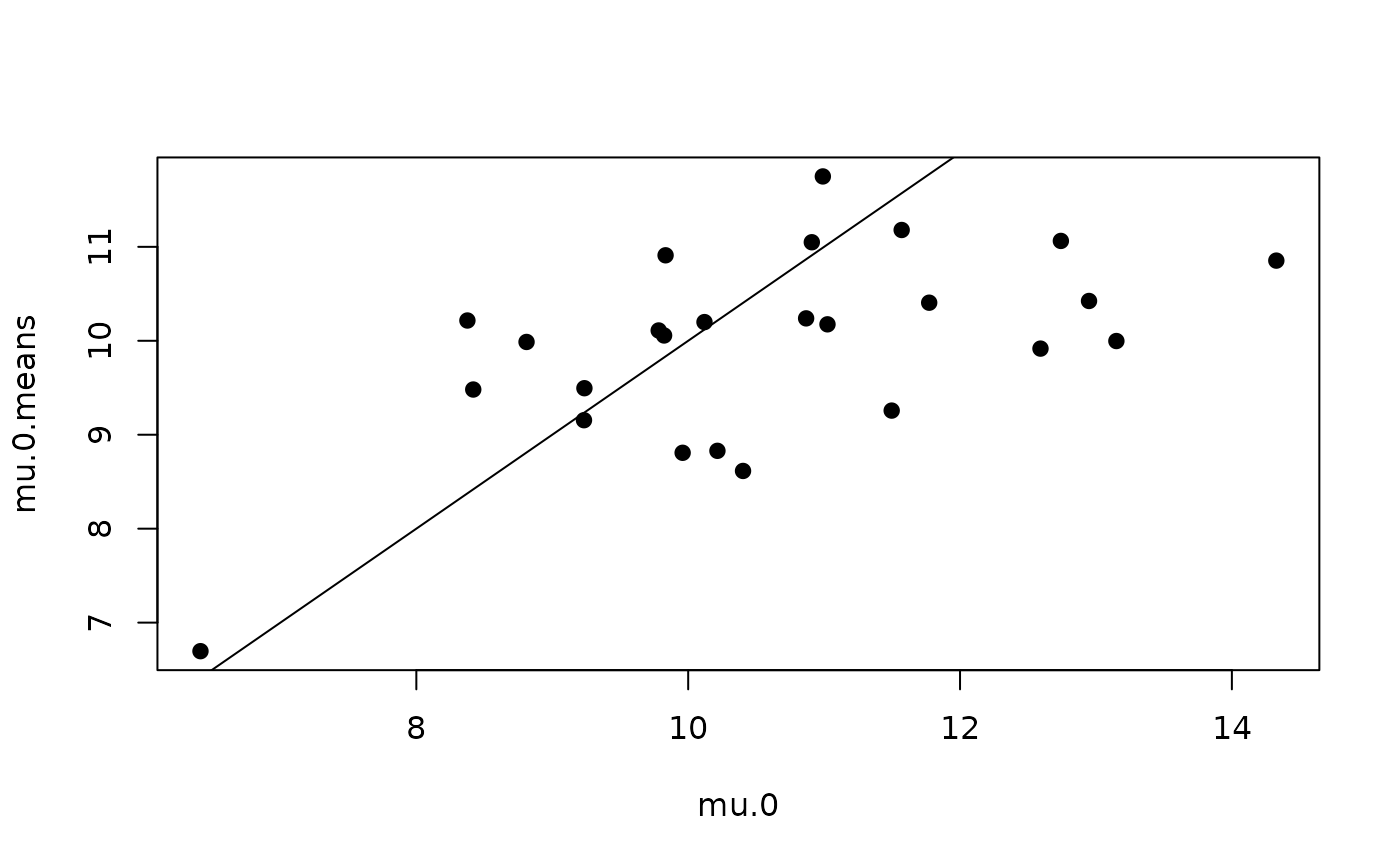
mu.0.means <- apply(out.pred$mu.0.samples, 2, mean)
mu.0 <- dat$mu[pred.indx]
plot(mu.0, mu.0.means, pch = 19)
abline(0, 1)