Estimating Forest Attributes
Jeffrey W. Doser, Hunter Stanke
2019 (last updated June 26, 2026)
Source:vignettes/basicEstimation.Rmd
basicEstimation.RmdNow that you have loaded your FIA data into R, it’s time to put it to
work. Let’s explore the basic functionality of rFIA with
tpa(), a function to compute tree abundance estimates (TPA,
BAA, & relative abundance (%)) from FIA data, and
fiaRI, a subset of the FIA Database for Rhode Island
including all inventories from 2013-2018.
The two example datasets used below are included with
rFIA. You can copy and paste the code below directly into R
to follow along without having to download any data!
Spatial and temporal queries
Are you only interested in producing estimates for a specific
inventory year or within a portion of your state? clipFIA()
allows you to easily query (subset) your FIA.Database
object so you only use the data you need. This will conserve RAM on your
machine and speed processing time.
Most recent subsets
To subset only the data needed to produce estimates for the most
recent inventory year (2018 in our case), users can simply pass their
FIA.Database object to clipFIA(), or more
explicitly specify mostRecent = TRUE in the call:
Spatial subsets
To subset the data required to produce estimates within a
user-defined areal region (should be contained within the spatial extent
of the FIA.Database object), simply pass a spatial polygon
object (from sp or sf packages) to the
mask argument of clipFIA. While
sp polygon objects continue to be supported, we highly
encourage the use of sf objects given that sp
is slowly being depracated in favor of sf. In our example
below, the spatial subset does little to reduce the size of our
FIA.Database object, although the effect is likely to be
much more substantial if applied to a larger state or region.
Basic population estimates
To produce tree abundance estimates and associated sampling errors
for the state of Rhode Island, simply hand your
FIA.Database object to the db argument of
tpa():
# TPA & BAA for the most recent inventory year
tpaRI_MR <- tpa(riMR)
# All inventory years available (i.e., returns a time series)
tpaRI <- tpa(fiaRI)If you would like to return estimates of population totals (e.g.,
total trees) along with ratio estimates (e.g., mean trees/acre), specify
totals = TRUE in the call to tpa(). All
estimation functions in rFIA by default return the sampling
error (i.e., standard error / mean * 100) as a measure of uncertainty in
the population estimates. Continue reading to see how confidence
intervals can be constructed from the sampling error.
Basic plot-level estimates
To return the same estimates at the plot level (e.g., mean TPA &
BAA for each plot), specify byPlot = TRUE. For tree-level
estimates, specify the argument treeList = TRUE, which will
return a tree list. The tree list can easily be used with the
customPSE() function to generate population estimates for
custom variables.
Grouping by species and size class
What if I want to group estimates by species? How about by size
class? Easy! Just specify bySpecies and/ or
bySizeClass as TRUE in the call to
tpa. By default, estimates are returned within 2 inch size
classes, but you can make your own size classes using
makeClasses()!
Grouping by other variables
To group estimates by a variable defined in the FIA Database (other
than species or size class), pass the variable name to the
grpBy argument of tpa(). You can find
definitions of all variables in the FIA Database in the the FIA
User Guide. Variables of interest will most likely be contained in
the condition (COND), plot (PLOT), plot geometry (PLOTGEOM), or tree
(TREE) tables.
# grpBy specifies what to group estimates by (just like species and size class above)
# NOTICE the variable names passed to grpBy are NOT quoted
# Ownership Group
tpaRI_own <- tpa(riMR, grpBy = OWNGRPCD)
# Ownership Group (for all available inventories)
tpaRI_ownAll <- tpa(fiaRI, grpBy = OWNGRPCD)
# Site Productivity Class
tpaRI_spc <- tpa(riMR, grpBy = SITECLCD)
# Forest Type
tpaRI_ft <- tpa(riMR, grpBy = FORTYPCD)
# Combining multiple grouping variables: Site Productivity within Forest Types
tpaRI_ftspc <- tpa(riMR, grpBy = c(FORTYPCD, SITECLCD))Variable names passed to grpBy should NOT be quoted.
Multiple grouping variables should be combined with c(),
and grouping will occur hierarchically. For example, to produce separate
estimates for each ownership group within ecoregion subsections, specify
c(ECOSUBCD, OWNGRPCD).
Unique areas or trees of interest
Do you want estimates for a specific type of tree (e.g., greater than
12-inches DBH and in a canopy dominant or subdominant position) in a
specific area (e.g., growing on mesic sites)? Each of these
specifications are described in the FIA Database, and all
rFIA estimator functions can leverage these data to easily
implement complex queries!
For conditions related to trees of interest (e.g., diameter, height,
crown class, etc.) pass a logical statement to treeDomain.
For conditions related to area (e.g., ecoregions, counties, forest
types, etc.), pass a logical statement to areaDomain.
These statements should NOT be quoted.
# Estimate abundance of trees greater than 12-inches DBH in a dominant
# or subdominant canopy position growing on mesic sites
tpaRI_domain <- tpa(riMR,
treeDomain = DIA > 12 & CCLCD %in% c(1,2),
areaDomain = PHYSCLCD %in% 20:29)In the code above, DIA describes the DBH of stems, CCLCD their canopy position, and PHYSCLCD the physiographic class upon which the class occurs. You can find definitions of all variables in the FIA User Guide. Variables of interest will most likely be contained in the condition (COND), plot (PLOT), plot geometry (PLOTGEOM), or tree (TREE) tables.
Visualization
Now that we have produced some estimates, we should translate them
into plots so we can easily see the status and trends in our selected
forest attributes. Using plotFIA(), we can easily produce
(1) simple or grouped time series plots, (2) simple or grouped plots
with a user defined x-axis (e.g., size class), and (3) spatial
chloropleth maps (see Incorporating
Spatial Data).
Time Series Plots
By default, plotFIA() will produce time series plots if
you produced estimates for more than one reporting year and do not
specify a non-temporal x-axis. To produce a grouped time series, simply
hand the grouping variables to the grp argument of
plotFIA() (should correspond with the grpBy
argument of estimating function).
# Using our estimates from above (all inventory years in RI)
plotFIA(tpaRI, y = BAA, plot.title = 'Simple Time Series')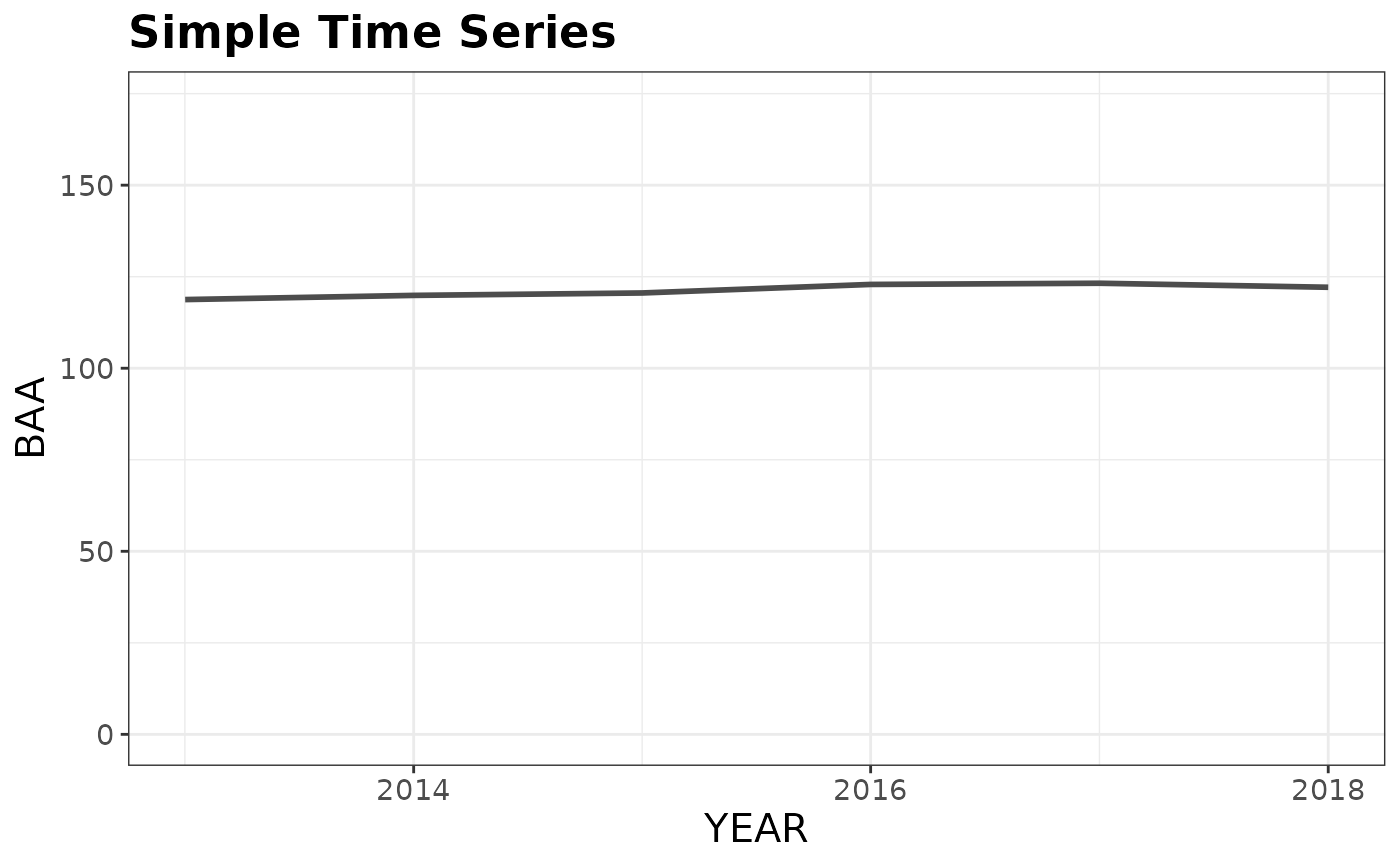
# Grouped time series by ownership class
plotFIA(tpaRI_ownAll, y = BAA, grp = OWNGRPCD,
plot.title = 'Grouped Time Series (Ownership Group)')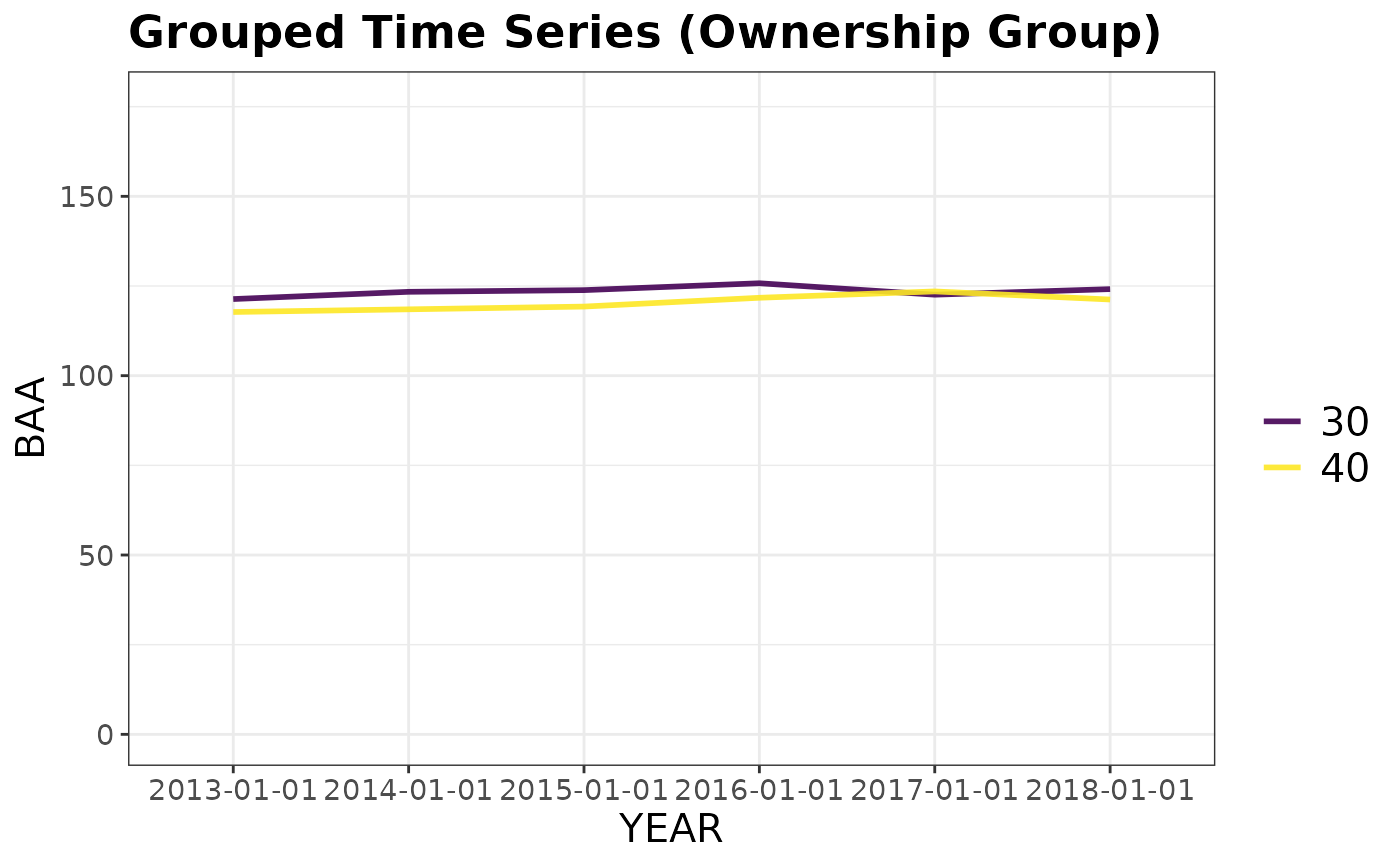
Non-temporal plots
To define your own x-axis, simply specify the variable you would like
to use in the x argument of the plotFIA()
call. This is great for plotting things like size-class distributions.
Since these plots do not have time as an axis, they are best suited for
plotting estimates from a single point in time (e.g., a most recent
subset).
# BAA by size class for most recent inventory
plotFIA(tpaRI_sizeClass, y = BAA, x = sizeClass, plot.title = 'Simple size class distribution')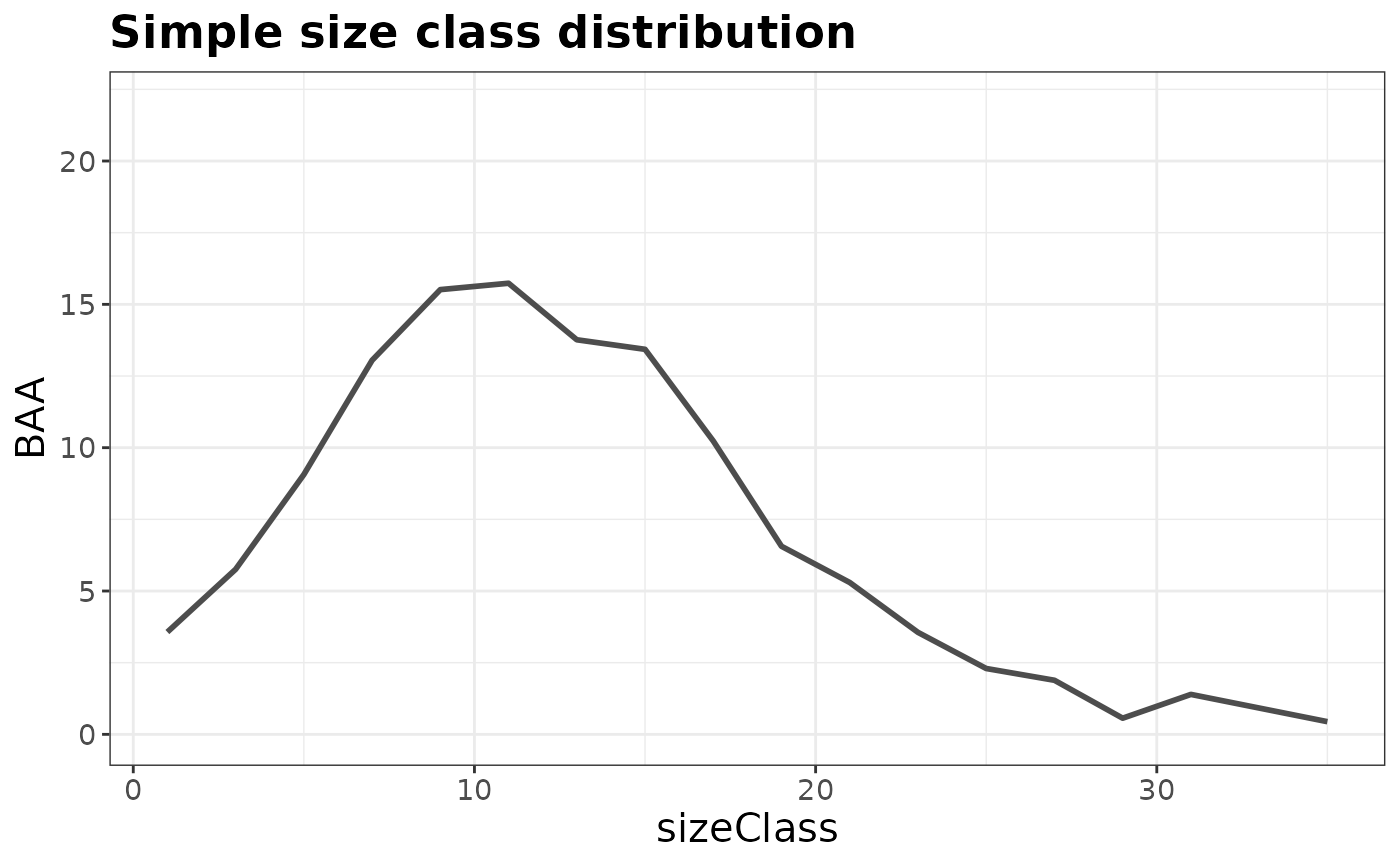
# Size class distribution for the five most common species in the
# most recent inventory of RI
plotFIA(tpaRI_spsc, y = BAA, grp = COMMON_NAME, x = sizeClass,
n.max = 5, plot.title = 'Grouped size class distribution')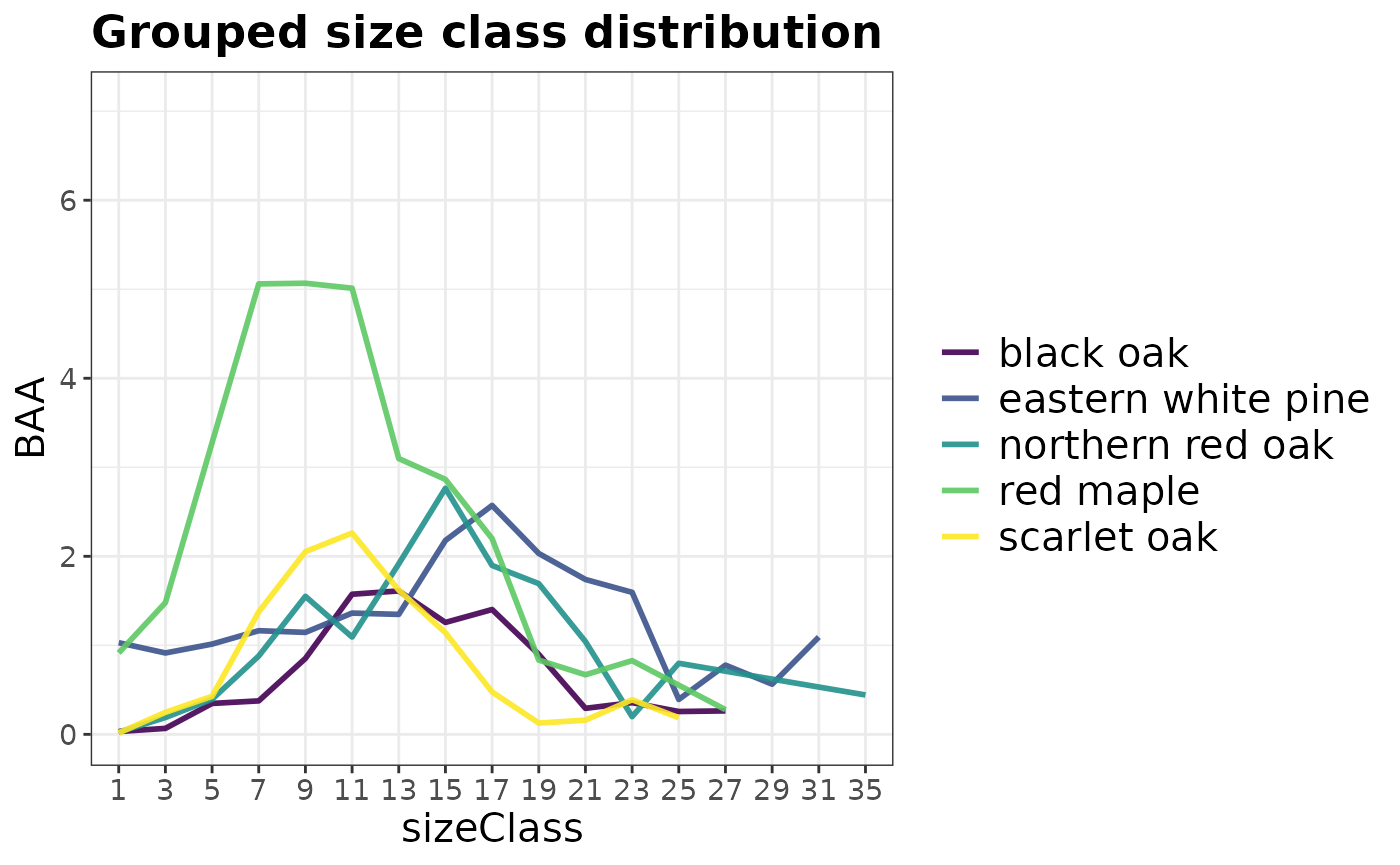
You can specify n.max to any grouped call to
plotFIA to only display the top or bottom n
groups in your plot. In the call above we specified
n.max = 5, resulting in the species with the highest
average basal area per acre values being plotted. To only plot the
bottom five, specify n.max = -5.
Sampling Error and Confidence Intervals
FIA’s flagship online estimation tool, EVALIDator, reports estimates of uncertainty as “% sampling error” (SE). This is an intuitive way to assess the amount of uncertainty in a population estimate, particularly when you are comparing uncertainty in estimates with very different absolute values (i.e., how large is the “spread” relative to the mean?). It is defined as the standard error divided by the sample estimate multiplied by 100. A downside to the percent sampling error is that it breaks down as the mean approaches zero (i.e., SE approaches infinity in this case), and so it is not always particularly useful for change estimates that tend to be near zero.
Fortunately, we can easily derive confidence intervals directly from SE. One approach is to use a normal approximation, which works well when sample sizes are large and the distribution of population values is not extremely skewed. Thus, a simple confidence interval takes the following form:
The term
is equal to the standard deviation of the sampling distribution of the
post-stratified estimator (i.e., the standard error).
is the z-value from the normal distribution.
is the confidence level which determines the percentage confidence one
has in the interval (i.e.,
for a 95% confidence interval). Doing this calculation with
rFIA is as simple as the following couple lines of
code.
tpa_est <- tpa(riMR)
# Margin of error for 95% confidence interval with a normal approx.
moe <- qnorm(0.975) * tpa_est$TPA_SE * tpa_est$TPA / 100
# Lower bound
tpa_est$TPA - moe ## [1] 371.2496
# Upper bound
tpa_est$TPA + moe## [1] 482.1742The normal approximation works well when sample sizes are adequately
large. This approach will work in many rFIA use cases, and
it is the approach recommended or provided by other FIA software such as
EVALIDator and the FIESTA R package. However, when generating estimates
that have small sample sizes (e.g., TPA within individual counties) it
may provide a confidence interval that is more precise than it should
be.
A more statistically accurate approach would be to replace the
value in the above with a
value from the Student’s t distribution. This requires also specifying
the degrees of freedom, which in this case corresponds to
.
Now, that leads to the question of what is
?
The exact answer will depend somewhat on the estimate that you are
generating. For most forest parameter estimates in rFIA,
one should use the number of plots used to compute land area estimates
(i.e., nPlots_AREA). For certain estimates of change, it
may be more reasonable to use nPlots_TREE, which would
ensure that only plots with the necessary requirements for informing the
sample are used in the degrees of freedom calculation.
# Margin of error for 95% confidence interval with a normal approx.
moe_t <- qt(0.975, df = tpa_est$nPlots_AREA - 1) * tpa_est$TPA_SE * tpa_est$TPA / 100
# Lower bound
tpa_est$TPA - moe_t## [1] 370.7118
# Upper bound
tpa_est$TPA + moe_t## [1] 482.7121Notice in this case, the estimates are nearly identical since the sample size is quite large (i.e., 127). The difference between the two approaches will increase as the sample size decreases.
Other rFIA functions
Fortunately, all of the rFIA estimator functions are
structured in the same way as tpa(). Therefore you can use
essentially the same argument calls we’ve used above to produce
estimates of other types of forest attributes! Notably, for some
rFIA functions like dwm() (estimates down
woody material volume, biomass, and carbon) it does not make sense to
include arguments like treeDomain or
bySpecies, and hence these arguments are not available. For
other functions, like area() or biomass(),
additional grouping options exist. Check out the help pages for these
functions for more details.